The storing and processing of data sets that contain personally identifiable information (PII) is increasingly regulated and is subject to onerous notification requirements when data breaches occur. Such data includes health information, financial data and legal records. When your business stores or processes this information and when it can be linked to a particular person, you are automatically subject to the applicable regulations.
Almost all companies and other organizations keep sensitive PII, whether it is in customer records, employee details or marketing profiles. As data breaches become more common (list of about 2000 major US health data breaches since 2009), the possibility that your business will expose private PII becomes more likely and the financial and reputational risks increase greatly. Data anonymization or de-identification is a method of reducing these risks and adding an extra layer of protection for your data.
How Data Anonymization Works
To prevent sensitive data from being linked to a particular person you have to prevent people from reading the identifying parts of the data. For example, a list of names of patients and their medical test results become just a list of test results when the names are illegible. The data is still useful and can be processed to calculate result averages and medical statistics but the results can no longer be linked to particular patients.
To render data anonymous, the data that includes PII can be encrypted. When IT security fails, the sensitive data cannot be read and linked to a particular individual. Under such a breach, the data in encrypted databases remains protected, and in almost all jurisdictions, regulations requiring data breach notifications do not apply.
As a result, the anonymization of data can allow organizations to avoid high notification costs. When PII records are encrypted, the remaining data can’t be linked to an individual. Even if the data is accessed by unauthorized persons, individual privacy is not compromised. Encryption is a tool that organizations can use to satisfy privacy regulations and prevent the application of notification requirements to their activities, even when hacked.
How to Anonymize Data
De-identification or anonymization of data involves the removal, encryption or masking of identifiers. The United States Department of Health and Human Services defines a list of such identifiers valid for health care data in the United States. Other jurisdictions may have different requirements. The challenge is to mask the identifiers relevant for the jurisdiction where the data is located.
Those identifiers have to be removed, encrypted or masked in relation to the individual concerned and in relation to relatives, employers and household members. The idea is to hide all identifying information so that the remaining, viewable data is truly anonymous.
Organizations are responsible for the anonymizing process and there may be additional references to identity not immediately obvious. For example, an employment profile that includes “former CEO” of a company would almost certainly identify the person. If you are aware that data contains additional information that could allow identification of an individual, you have to remove that information as well.
Using Data Masking to Anonymize Data in Process
Data masking is a form of encryption that renders data illegible without changing the type of data or its format. Instead, the individual characters of the data are replaced by other similar characters. For example, a masked name remains a text string and a masked credit card number remains a number.
This means fields that are programmed to accept certain types of data will remain functional with the masked data. Masking only the data fields that can be used to identify individuals lets you continue to work with the anonymized data. You can process, search and sort the data even while the PII fields are encrypted by masking. When you need to see an encrypted part of the data, you can unmask the data and work with complete records.
Data masking is especially advantageous when remote or mobile team members have to access data on servers in the cloud. With encrypted database files they have to download the whole file to find a record or they have to decrypt the file in the cloud, opening up a security gap. With data masking, they can execute searches and download what they need, unmasking the records on their own device if they have the corresponding authorization.
How CloudMask Anonymizes Data
CloudMask uses high security data masking to protect sensitive data. For databases containing PII, the fields allowing identification of individuals can be masked, fulfilling the requirements for anonymization. The application masks the sensitive data as you create it while leaving anonymous data in clear text. When you store or email the database file, the data remains anonymous and you retain the keys to decrypt the masked fields. Only when you authorize someone to read the masked part of the records can they see the PII and identify the people involved. You have seamless control of your data and your data remains protected at all times.
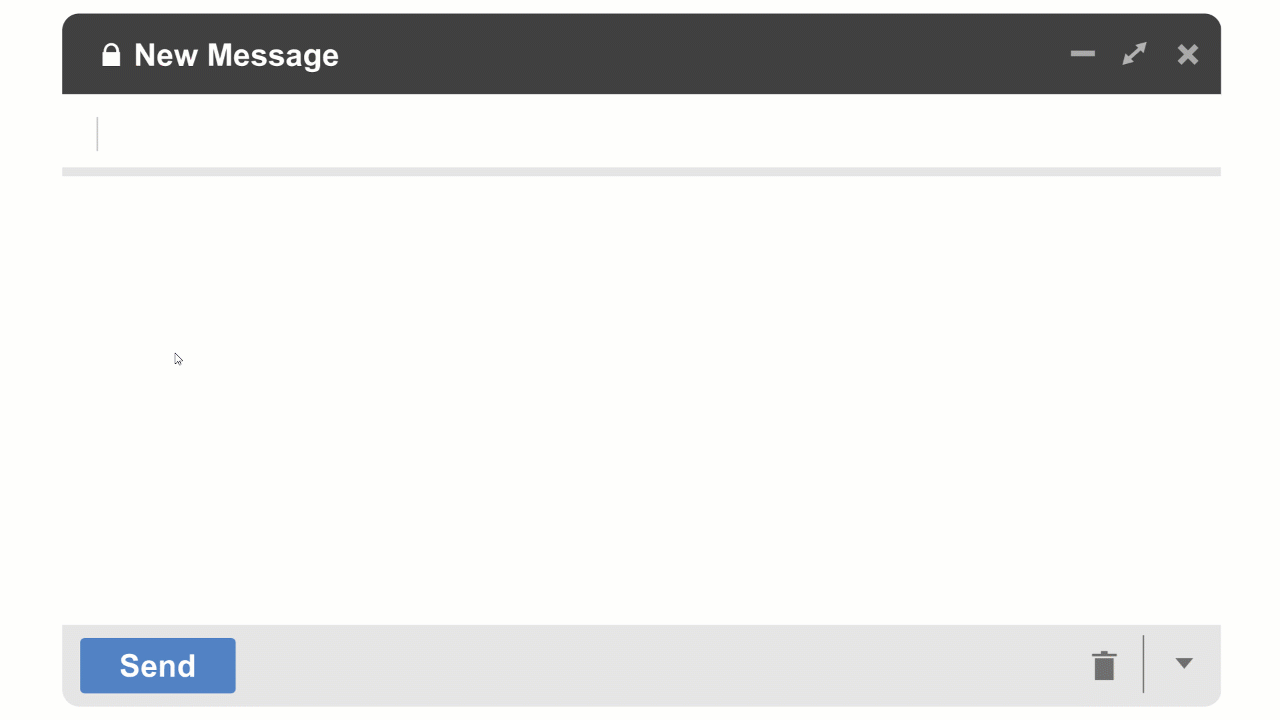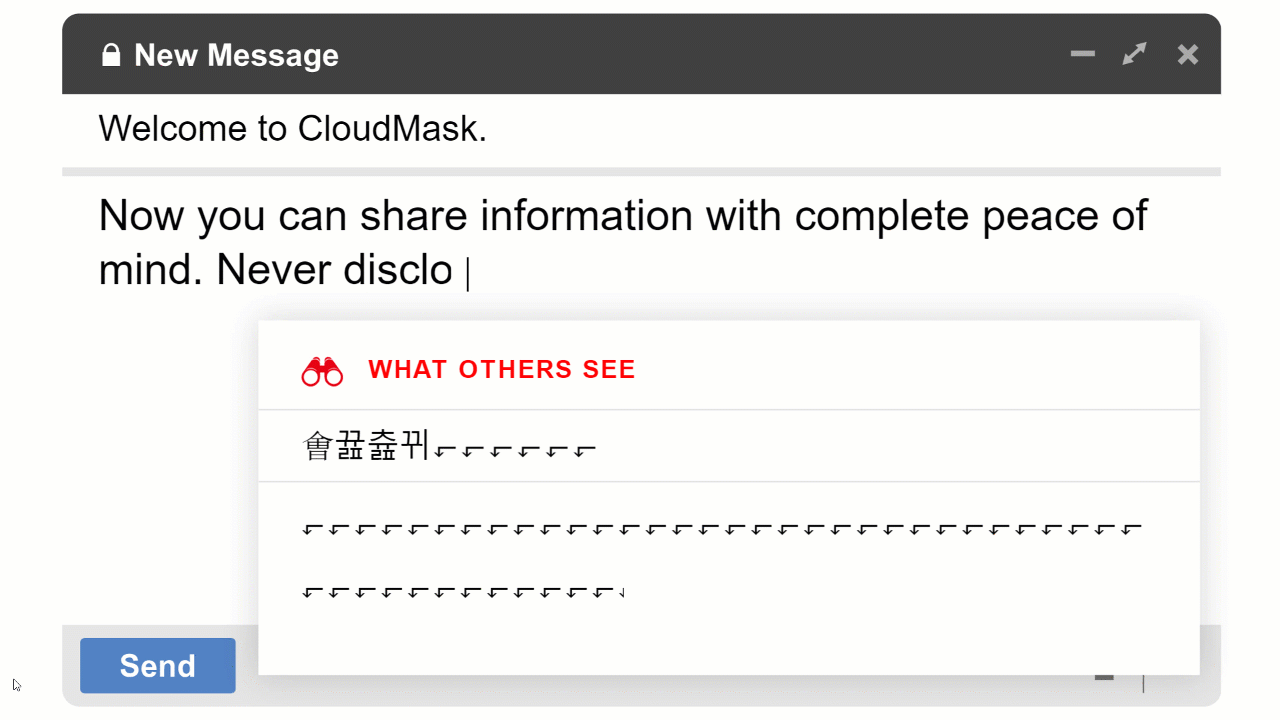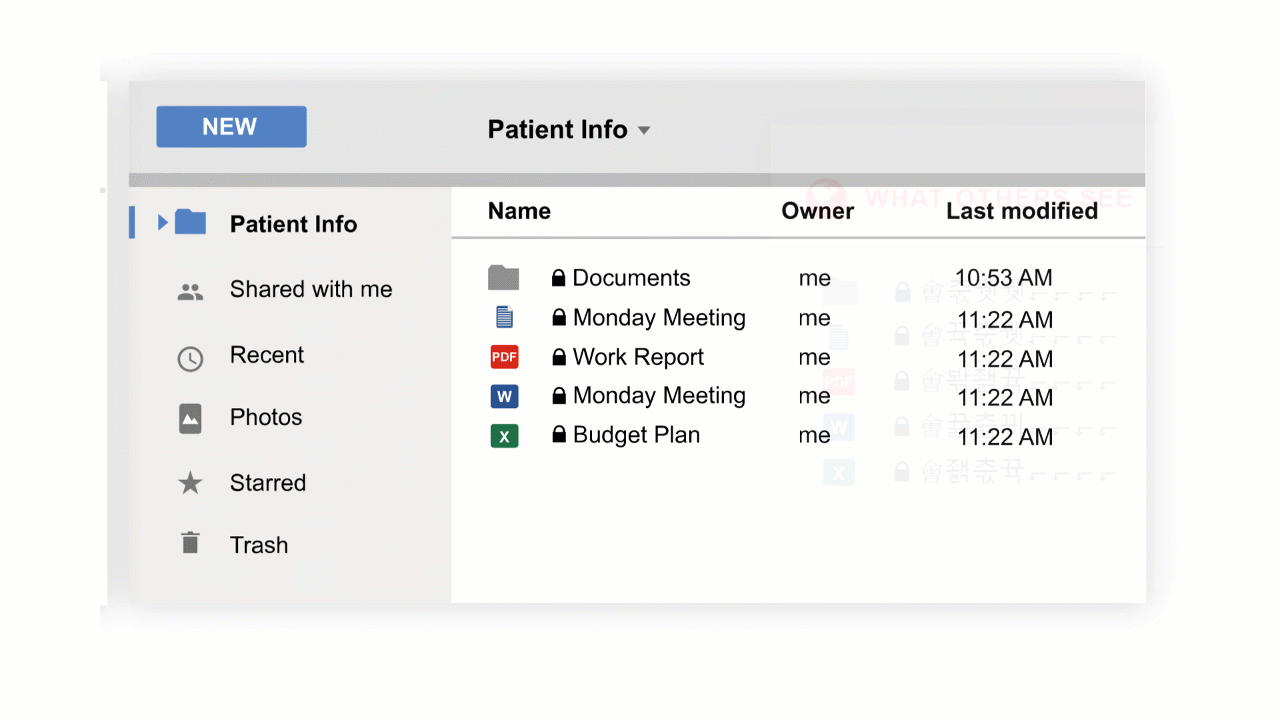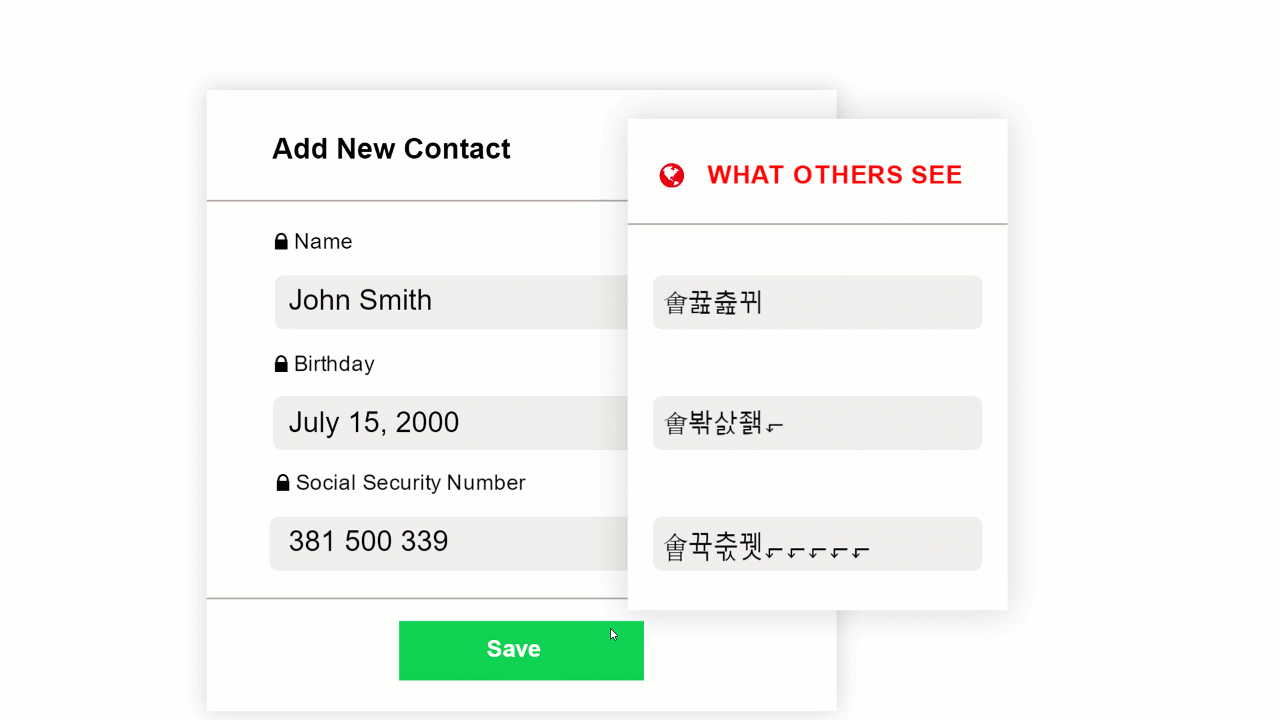
With CloudMask, only your authorized parties can decrypt and see your data. Not hackers with your valid password, Not Cloud Providers, Not Government Agencies, and Not even CloudMask can see your protected data. Twenty-six government cybersecurity agencies around the world back these claims.

Watch our video and demo at www.vimeo.com/cloudmask